Table of Contents
Abstract
Keywords
Current Approaches
Traditional Expert System Development
Methodology
RIME
Connector
Assembly Specification Expert (CASEy)
Maintenance Anomalies in Rule Bases
The TRIMM Methodology
The TRIMM Life Cycle
List of Figures:
Figure 1: Knowledge Map
Figure
2: Rule Cluster Construction
Figure 3: Rules
Dictionary Entry
Figure 4: Conditions Dictionary
Entry
Figure 5: Constructing a Decision Table
Relation
Figure 6: EZ-Xpert Simplification
The Relational Intelligence Management Methodology, TRIMM, is a full life-cycle development methodology for rule based systems that is focused on low maintenance demands, long-term accuracy, and verifiability. It has been implemented in the expert system development tool EZ-Xpert.
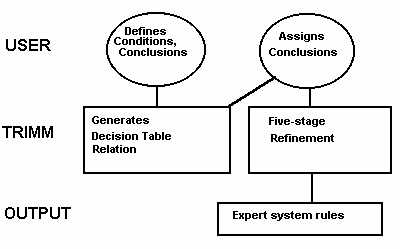
TRIMM uses a central Knowledge Dictionary containing definitions of rule clusters, conditions, and conclusions to create individual rules. The expert assigns conclusions to each rule. Local verification is performed on each rule cluster, while global verification is performed using the Knowledge Dictionary. Each rule cluster is then refined in five stages and code is generated for the host environment.
TRIMM takes a CASE approach to create high-performance, maintainable systems that meet the six classes of verification criteria and minimize maintenance anomalies. This paper presents a detailed explanation of how these characteristics may be enforced in an expert system.
Keywords: Expert systems, rule bases, normalization, simplification, decomposition, anomalies.
Experience shows that a production expert system is a very difficult class of software to create and maintain. Major difficulties include knowledge acquisition, verification, testing, and maintenance. A recent editorial hints at the problem: in an informal survey, delivered expert system covered only 60 to 95% of the search space [8]. XCON, cited by many as the example of a successful production expert system, has a stated accuracy of 95%. This level of performance is unacceptable in any other class of software; it is totally unacceptable for a class of software that aspires to intelligence. TRIMM attacks these problems by using a simple, structured approach to defining, developing, and generating the system. It creates accurate, verified, maintainable expert systems.
Accuracy is of paramount importance in an expert system. However, most experts [18] consider exhaustive testing impractical. This difficulty brings into question the accuracy of the rule base. TRIMM generates code through a syntactic transformation of the specifications, guaranteeing a 100% accurate implementation of the specifications.
To ensure accuracy of the specifications, TRIMM transparently eliminates many verification problems. The generated rule-based systems are free from incompleteness, implicit maintenance anomalies, contradictions, irrelevant tests, redundant rules, conflicting rules, subsumed rules, illegal attribute values, unreferenced attribute values, dead-end conditions, dead-end goals, and circular rules.
Maintenance has been identified as a major problem for volatile expert systems. XCON requires that half of the code be re-written each year [3]. Because of high maintenance demands, CAT has been taken out of service and XCON has been re-implemented in a low-maintenance environment called RIME [1]. RIME refines the knowledge in XCON through decomposition [2]. In other approaches to refinement, the ID3 simplification algorithm [16] lowers maintenance volume. TRIMM employs five stages of knowledge refinement to lower maintenance and enhance computational efficiency.
TRIMM accurately generates code that implements the current specifications. It ensures that each iteration of the system is accurate to the specifications, maintainable, verified, and efficient. This paper will first present an overview of current methodologies and maintenance anomalies, then present The Relational Management Methodology (TRIMM), discuss the limitations of TRIMM, and conclude with ideas for further research in this domain.
The traditional development methodology, referred to by Boehm as the Spiral Methodology [4], consists of a continuous cycle of: (1) Set requirements, (2) Design the system, (3) Translate to rules and facts, and (4) Implement the prototype. Additionally, approaches to building low-maintenance expert systems have been put forward. The first one presented, RIME, is a methodology used to lower maintenance for XCON. The next, CASEy, was designed by The Boeing Company to be a low-maintenance methodology.
Traditional Expert System Development Methodology
Traditional expert system development has adopted a prototype approach similar to that of procedural software, but more iterative in nature. The first iteration is a small prototype that addresses an interesting subset of the problem area and is used to evaluate the match between the problem and an expert systems solution. If an expert system is not a good solution, it will be discovered inexpensively; if it is a good solution, the successful prototype will help to gain additional support for the project. Each iteration in the cycle expands and refines the existing system until it meets the business needs of the company.
Holsapple and Whinston [13] define seven developmental stages:
A similar development plan is presented in [9]. The following steps occur: define the problem, build a prototype, develop the system, evaluate it, integrate it into the business environment, and maintain it. Maintenance is made explicit in this plan, but not the iterative nature. The traditional procedural software prototype approach specifies these steps: define the system, design it, extend and refine it, then deliver, maintain and evaluate it. At an overview level, expert systems follow a similar path and add the notion that development is more iterative and uncertain.
XCON is a major factor in business strategy and information for DEC, and models a highly volatile environment. First placed in production use in 1980 with about 700 rules, XCON returned revenues of $20 million [14]. But maintenance threatened the profitability of the system that had grown to over 10,000 rules and rumors abounded that the system was in trouble [1]. However, recent publications indicate that the system is again profitable because of a switch to RIME, a methodology developed by the Configuration Systems Development Group (CSDG) at DEC, which is designed to reduce maintenance [2].
RIME consists of three components: development plan, control characteristics and rule base characteristics. The development plan is not a radical proposal; it specifies an iterative process of definition, refinement, extension, delivery and evaluation. The RIME control structure decomposes a problem into one of three types: procedural, declarative, or decision-related. Each is implemented in a slightly different manner, but the overall strategy is to decompose the problem. The same strategy used for control is carried over to the rule base.
RIME maintainers believe that the new rule base is much more homogeneous and predictable than the old system and is easier to understand and maintain. They can locate the appropriate code faster and understand it well enough to perform maintenance [3]. RIME is judged to be successful by its designers because it has made maintenance more manageable.
Connector Assembly Specification Expert (CASEy)
A similar methodology is used by the CASEy system. CASEy is a production expert system utilized by the Boeing Company to determine the proper specifications for an electrical connector assembly [5]. The specifications are contained in 20,000 printed pages, and the search is complicated by the need to examine many manuals and resolve conflicts between them before considering individual worker training and equipment to determine the correct specification. Previously, workers would take 42 minutes to determine the correct specification by looking in the manuals. CASEy normally supplies the information, printed for the user, in three to four minutes.
The rules in CASEy decompose the problem at a rate of one level of decomposition per rule, as opposed to evaluating several levels of decomposition and possibly several conclusions in the same rule. Control and rule base elements are naturally grouped into similar modules, leading to small, modular rules that are easily organized and standardized. The volatile portions of the environment, such as information about the worker and his tool inventory, are loaded in a run-time configuration file that is maintained by the user [5]. As with RIME, decomposition removes opportunities for explicit anomalies.
CASEy's environment is somewhat different from RIME's. RIME is based in OPS5, a forward-chaining system that fires all available productions and returns the best answer through conflict-resolution. The design philosophy of CASEy is to maintain a fully declarative environment because multiple answers are desirable, favoring a backward- chaining PROLOG environment over one with more procedural constructs, such as OPS-5 [5]. No side-effect firing of rules, as with the original XCON, is utilized; CASEy's developers are considering parallel processing if computational efficiency becomes a problem, as opposed to RIME's problem solving methods. These differences, however, are primarily implementation oriented and are not critical to this discussion. Furthermore, these differences are overshadowed by the similarities between CASEy and RIME: decomposition, modularity, standardized rules, and the use of external data stores (databases or configuration files).
Maintenance Anomalies in Rule Bases
E. F. Codd cemented himself a place in computer history by introducing the concept of update anomalies [6] and opened a fertile ground for database researchers, but the concept has been slow to migrate to the domain of rule based systems. However, as the same maintenance activities take place in both rule bases and databases, we should consider the implications of these activities on rule bases.
Three update anomalies occur in databases: insert, delete, and update. In rule bases, the conditions (corresponding to the database keys) must be unique only as a set, not individually, and null conditions are desirable. Therefore, the insert and delete anomalies do not occur in rule bases.
The third anomaly, the update anomaly, occurs in both databases and rule bases. An update anomaly can take either of two forms. The implicit anomaly occurs when an condition is dependent on another condition. This implies that when the value of the first is updated, the value for the second must also be updated. If both are not updated correctly and simultaneously, the rule base (or database) is inaccurate. The explicit anomaly occurs when all instances of a condition are not updated consistently. A more complete discussion of rule base structure and maintenance anomalies can be found in [12] in this issue.
Implicit anomalies can be eliminated by a process analogous to database normalization. Removal of implicit anomalies, as in databases, cannot be performed algorithmically because a computer program cannot distinguish between functional dependencies and a coincidental pattern in the data. The rule base builder must identify and treat implicit anomalies.
The opportunities for explicit anomalies can have two causes. One cause is insufficient decomposition resulting in a greater number of occurrences of each variable, and a correspondingly higher number of opportunities for an explicit anomaly. The second cause, irrelevant conditions in a rule set, are in themselves opportunities for explicit anomalies. Explicit anomalies can be minimized through decomposition and simplification, which can be performed algorithmically. Quinlan's ID3 is a well-known induction algorithm [16] which derives a simplified rule base containing fewer explicit anomalies. In the RIME re-implementation of XCON, decomposition is performed (although not algorithmically) to minimize explicit anomalies. It is not usually possible to remove all opportunities for explicit anomalies. Readers desiring more information on maintenance anomalies are referred to [10].
Now that we have introduced the concept of maintenance anomalies in rule bases, we can examine techniques to minimize their occurrence. In the next section, we will present the TRIMM Methodology.
The TRIMM Life Cycle is similar to those previously described. The uniqueness of this approach is extensive local and global verification, five stage knowledge refinement to derive an appropriate structure for the rules and derive the most concise rule set, and the use of a central Knowledge Dictionary consisting of a Rules Dictionary, a Conditions Dictionary, and a Conclusions Dictionary.
Verification is performed at two levels. Global verification analyses the Rules Dictionary to ensure, for example, that all conditions may be instantiated. Local verification is performed on each rule cluster to ensure criteria such as completeness. Because the Knowledge Dictionary ensures a closed world, local verification criteria are met for a rule base a whole if they are met for each rule cluster. Readers desiring more information on rule structures and refinement are referred to [10], and those desiring more information on two-tier verification are referred to [11]. An overview of two-tier verification can be found in [12] in this issue.
The TRIMM life cycle is an iterative cycle of the following steps: definition, construction, refinement, testing, delivery, evaluation, and maintenance. The cycle continues until the specifications are complete and correct. Each iteration produces a rule base that implements correctly the current specifications. TRIMM breaks no new ground in testing, delivery, and evaluation. We will, therefore, concentrate on those steps where TRIMM differs from common practice.
The initial step in any project is definition. This step is devoted to studying the problem and defining the parameters for the project, determining the feasibility of a successful project, and defining the limits to which the system is to perform. Users are brought in to aid in interface requirements and necessary functions. Other aspects to be considered are knowledge accessibility, sponsor strength, availability of (cooperating) experts, consistency between experts, and if the in-house capability to build or maintain the system exists.
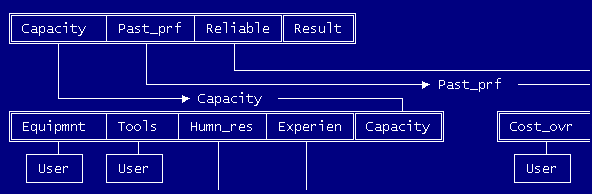
The output of this stage is a Knowledge Map for this iteration of the system, such as the map of the Contract sample system shown in Figure 1. The Knowledge Map is derived from the entries in the Rules Dictionary and shows the relationships between the rule clusters that make up the rule base. It also shows how each condition and conclusion is instantiated.
There are two classes of global verification criteria: instantiation and domain constraints. The Knowledge Map can be evaluated for the following global instantiation verification criteria [11]: cycles, conclusions that do not match a condition or goal, conditions or conclusions that have no source such as a question of the user or another set of rules, and duplicate or subsumed rule clusters.
The structure of the rule clusters should also be considered. Each condition in the rule cluster should be independent of the others; if not, normalization should be performed [10]. Rule clusters containing multiple conclusions should be evaluated to determine if decomposition is possible [17]. Each rule cluster should contain the minimal set of conditions necessary to determine a minimal set of conclusions (preferably one).
The next step in creating the system is to create the individual rule clusters. A rule base is composed of sets of rules (rule clusters) that use common conditions to reach the same conclusion(s). Each rule cluster must meet both local verification criteria and global domain consistency criteria. The classes of local verification criteria are the following:
Figure 2: Rule Cluster Construction
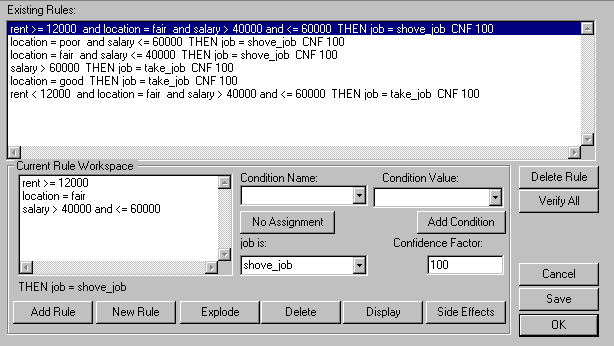
A central Knowledge Dictionary may be used to meet many verification criteria. The Rules Dictionary (see Figure 3) contains the conditions and conclusions used in each set of rules and information about the state of the rules. The Conditions Dictionary (see Figure 4) and Conclusions Dictionary store individual definitions for each condition and conclusion including legal values and source. In this way, the domain is explicitly stated, whereas it is normally implicitly stated in rules. Any implementation-specific characteristics, such as host language syntax and reserved words, may be verified during input.
Figure 3: Rules Dictionary Entry
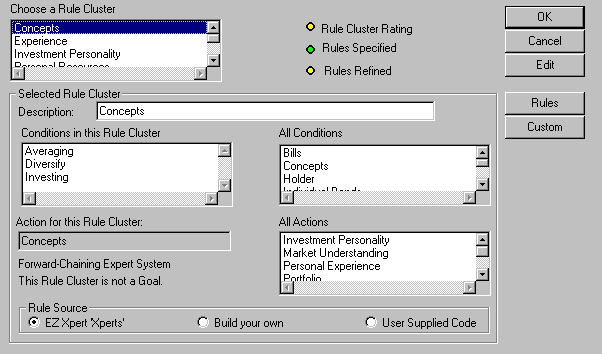
Figure 4: Conditions Dictionary Entry
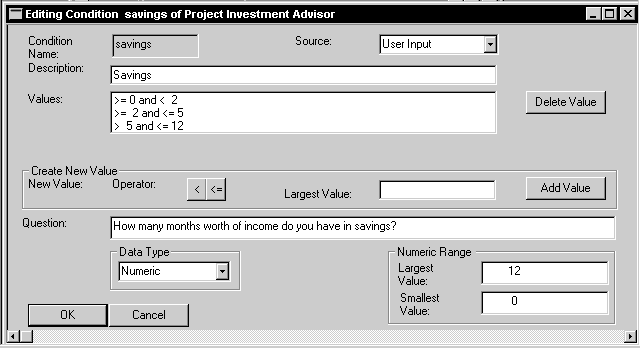
The source of each condition is also recorded. If the source is a fact, such as a database retrieval, a fact entered by the user, or a global variable, then no other action is needed. However, if the source is another set of rules, then another decision table is created. Thus, each decision table leads to the next until all goals have been specified and all conditions mapped to their source.
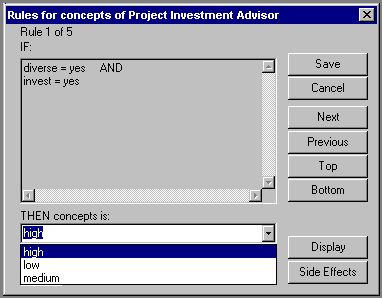
The Knowledge Dictionary entries are then used to create specifications. For each rule cluster, the Cartesian Product of condition values is generated and the expert assigns conclusions to each combination of condition values as shown in Figure 5, forming the decision table relation. Each row of condition and conclusion values is equivalent to an expert system rule. Local completeness, consistency, and domain constraints are assured. After each decision table relation is completed, it is examined by the expert for local accuracy. Note that we may display the specifications in any form desired. Many researchers describe testing the completed rule base, whereas TRIMM tests each component as it is created or maintained, as suggested in [15]. Each decision table is algorithmically refined after verification.
Figure 5: Constructing a Decision Table Relation
Refinement of the decision table is performed in five stages. First, normalization removes dependencies between conditions which cause implicit anomalies. Next, decomposition separates independent tasks, removing some opportunities for explicit anomalies. Normalization and decomposition also derive an appropriate structure for the rules. Simplification is performed in two stages, logical simplification and range simplification, to minimize explicit anomalies and derive the most concise expression of the knowledge. The final stage is host language tuning. The R5 Refinement Algorithms implemented in EZ-Xpert are detailed in [10].
Two approaches to simplification are the information-theoretic algorithm ID3 and the logical simplification approach used in EZ-Xpert. ID3 is faster, has more capacity, but achieves less simplification. The Chess end-game test set has 648 rules containing 4536 clauses. ID3 reduces it to 335 clauses, where EZ-Xpert reduces it to 60 clauses. The Lens test set has 24 rules containing 96 clauses. ID3 reduces this test set to 31 clauses, where EZ-Xpert simplifies it to 25 clauses. These test sets contain only text data, but logical simplification can be extended to simplify numeric and date ranges. A sample refinement using numeric range simplification is shown in Figure 6. With any simplification approach, incremental simplification and an UNDO capability are desirable.
Figure 6: EZ-Xpert Simplification
As each new decision table is defined, relationships between it and other decision tables are retained in the global Knowledge Dictionary for performing global verification. After refinement is complete, explanations and confidence factors are added if desired.
When all decision table relations have been defined and refined, we may generate code. EZ-Xpert generates code through a syntactic transformation of the specifications. In this manner, the executable is directly derived from the specifications while we avoid typos, syntax errors, and other run-time related errors.
Testing verifies both the specifications and the implementation, and takes two forms. Accuracy testing is performed by an expert to ensure that the specifications are correct, and test cases exercising as much of the knowledge as possible are used. Usability testing is performed by a typical user to determine if the system is usable in the work environment.
When the system meets the organizations needs, it must be delivered to the users. The software must be installed on user's equipment. Users must be trained, documentation must be provided, and on-going help must be available. This is a critical period in the acceptance of a system and should be well-planned.
The system should be monitored after delivery to determine its effectiveness in areas such as accuracy, usability and computational efficiency.
The major motivation of TRIMM is long-term accuracy of the knowledge. In TRIMM, structural maintenance is performed by modifying the Knowledge Dictionary, which in effect changes the specifications. The three major maintenance operations are add, delete and edit. Adding a condition is accomplished by adding the specification that the new condition be tested. An appropriately modified decision table is generated and the mapping to conclusions re-evaluated. If the new condition's value is not determined by a source, a new decision table is generated to determine it's value, and the Knowledge Dictionary is updated to reflect the new specifications. Deletion is accomplished in a similar manner. Editing consists of changing the specifications for a condition or conclusion. A significant advantage of this approach is that knowledge, not code, is maintained. Refinement is performed after maintenance and verification are completed.
After a rule cluster has been refined, changes to the conclusions of rules must be evaluated for conflicts. No other local verification testing is necessary after the decision table relation is created.
The Cartesian product used in TRIMM may be inappropriate for certain domains because of combinatorial explosion. In the vast majority of systems, the verification benefits of the Cartesian product outweigh its cost when combined with refinement.
As described in this paper, TRIMM derives monotonic, backward-chaining, propositional systems. The extension to forward-chaining is straight-forward. Non-monotonic situations are currently addressed only by changing the specifications. Predicate calculus is not supported.
The algorithms used seek maximum accuracy at the cost of computational efficiency. We argue that the cost during development is recovered many times by the computational efficiency of the delivered implementation.
This research is being implemented in an expert system development environment named EZ-Xpert. The motivation behind EZ-Xpert is to enable the expert to develop reliable, low-maintenance expert systems in a menu-driven and fill-in-the-blank environment. EZ-Xpert derives expert systems that contain no implicit anomalies, contain minimal explicit anomalies, are complete, contain no contradictions, contain only reachable rules, contain no duplicate rules, contain no inconsistency, contain no syntax errors, are computationally efficient, and require minimal storage space.
More research is necessary to determine the optimum algorithms for refinement. The R5 Algorithms used in TRIMM favor completeness over computational complexity. More efficient algorithms will speed the development process. The environment described here lends itself to deductive database systems. In this manner, executable specification can be realized. Again, more research is needed to make these systems practical for everyday use.
A final advantage of the CASE approach is speed. The Contract sample file initially contains 147 rules with 477 clauses in them. The refined version of the file contains 88 rules with 247 clauses. The entire process of defining six rule clusters, defining nineteen conditions, defining six conclusions, specifying 147 rules, refining the rules, and generating verified, ready-to-run code took less than a half hour.
This research is funded in part by a grant from First Interstate Bank.
[1] AI Trends, High Technology, September 1988.
[2 ] Bachant, Judith and Soloway, Elliot. The Engineering of XCON. Communications of the ACM, Volume 32, Number 3, March 89.
[3] Barker, Virginia E. and O'Connor, Dennis E. Expert Systems for Configuration at Digital: XCON and Beyond. Communications of the ACM, Volume 32, Number 3, March 1989.
[4] Boehm, B. W. A Spiral Model of Software Development and Enhancement, ACM Software Engineering Notes, March 1985.
[5] Interview at Boeing Computer Services Electronic Support (Bill McClay), Seattle, Washington, August 1988.
[6] Codd, E.F. A Relational Model of Data for Large Shared Data Banks. Communications of the ACM, Volume 13, Number 6, 1970.
[7] Date, C.J. An Introduction to Database Systems, Volume 1. Addison-Wesley, 1986.
[8] Eliot, Lance. Verification in Expert Systems, AI Expert. July 1992.
[9] Harmon, Paul and King, David. Expert Systems: Artificial Intelligence in Business. John Wiley Publishing, 1985.
[10] Hicks, Richard C. Maintenance Anomalies in Rule-Based Expert Systems, Journal of Computer Information Systems, Winter, 1994.
[11] Hicks, Richard C. Two-tier Verification for Rule-Based Expert Systems, Journal of Computer Information Systems, to appear.
[12] Hicks, Richard C. Verification Properties of Knowledge Dictionaries for Expert Systems, Heuristics: The Journal of Intelligent Systems, Fall 95.
[13] Holsapple, Clyde W. and Whinston, Andrew B. Business Expert Systems, Irwin Publishing, 1987.
[14] McDermott, J. R1: A Rule-Based Configurer of Computer Systems, Artificial Intelligence, Volume 19, 1982.
[15] Nguyen, T.A., Perkins, W.A., Laffey, T.J. and Pedora, D. Checking an Expert System for Consistency and Completeness. Proceedings of the Ninth International Joint Conference on Artificial Intelligence, 1985.
[16] Qunilan, J. R. Simplifying Decision Trees, Knowledge Acquisition for Knowledge-Based Systems. Gaines, B. and Boose, J. editors. Academic Press, 1988.
[17] Soloway, Elliot, and Bachant, Judy, and Jensen, Keith. Assessing the Maintainability of XCON-in-RIME: Coping with the Problems of a VERY Large Rule-Base. Proceedings of AAAI-87, Volume 2.
[18] Stachowitz, Rolf, Combs, Jacqueline, and Chang, Chin L. Validation of Knowledge-Based Systems. Proceedings of the Second AIAA-NASA-USAF Symposium on Automation, Robotics, and Advanced Computing for the National Space Program, Arlington, VA, 1987.
END